
在SQL面试中,很多候选人习惯拿到问题后直接写代码,却忽略了一个关键步骤——向面试官确认需求细节。曾有候选人因未确认"是否包含已注销学生"的条件,用INNER JOIN写出的结果遗漏了重要数据,最终不得不反复修改。
正确的做法是将面试视为与业务方的协作场景:先明确数据范围(如"学生表是否包含历史记录")、计算逻辑(如"GPA是否仅统计必修课程")、特殊要求(如"是否需要处理NULL值")。这些信息能帮你提前规避极端情况,比如事务数据库中常见的"学生表与课程记录表数据不同步"问题。
合并多表数据时,INNER/LEFT/FULL JOIN的选择直接影响结果完整性。以学生表(student)与课程记录表(class_history)为例:若面试官要求"列出所有选课学生(包括已注销)",需用LEFT JOIN保留左表全部记录;若仅需"当前在读学生的选课情况",则INNER JOIN更合适。
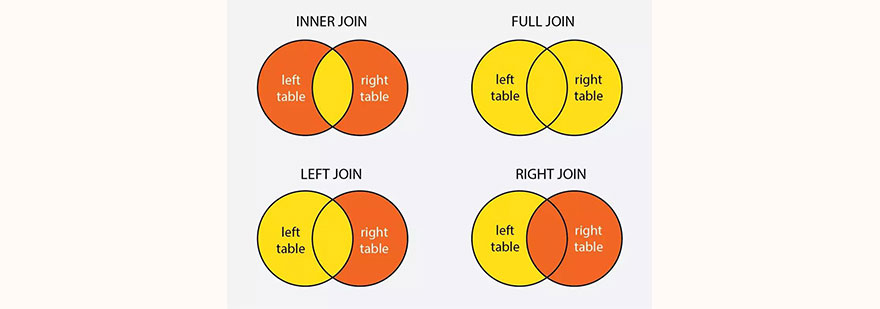
值得注意的是,RIGHT JOIN因不符合阅读习惯(左表逻辑更直观),建议用LEFT JOIN替代。例如"右表全部记录+左表匹配记录"可通过交换表顺序并使用LEFT JOIN实现。
当遇到"计算各学生各学年平均GPA"这类聚合需求时,GROUP BY是核心工具,但WHERE和HAVING的使用边界常被混淆。以"筛选必修课程(is_required=TRUE)且平均GPA≥3.5的学生"为例:

需特别注意:SELECT中定义的别名(如avg_gpa)无法在WHERE/HAVING中提前引用,因为SQL引擎的执行顺序是"FROM→WHERE→GROUP BY→HAVING→SELECT"。
RANK、DENSE_RANK、ROW_NUMBER的区别是面试必问点。假设某部门有3名员工绩效相同:
LAG/LEAD函数常用于计算环比数据(如"当前月与上月销售额对比")。例如,通过"LAG(sales,1) OVER (ORDER BY month)"可获取前一月销售额,无需自连接。
真实数据中,重复值和NULL是常见问题。例如,用"employee_name"分组统计薪资可能因重名导致错误,正确做法是用"employee_id"唯一标识记录,再通过JOIN关联姓名。
处理NULL时,需先确认字段是否允许为空(如ID列通常非空,但备注列可能含NULL)。可通过"IS NULL"判断缺失值,用"COALESCE(salary,0)"将NULL替换为默认值(如0),避免聚合计算时出现偏差。
技术能力是基础,沟通能力决定上限。面试中应主动阐述思考过程:"我注意到class_history表可能包含已注销学生,需要确认是否保留这部分数据"、"这里选择LEFT JOIN是为了确保不丢失左表记录"。即使最终答案有小错误,清晰的逻辑表达也能让面试官看到你的数据思维。
总结来说,SQL面试的核心是"精准理解需求+正确使用工具+考虑边界条件+清晰表达思路"。掌握这些要点,就能在面试中从容应对各类挑战。
抢返现券

在线预约
 在线预约-让老师及时联系您!
在线预约-让老师及时联系您!手机访问
扫码访问
















































